les pneus¶
Vous vous souvenez peut-être que dans les slides on avait construit ceci :
# un code qui crée "à la main" les MultiIndex
# à des fins d'illustration seulement
import pandas as pd
import numpy as np
# index for years and visits
index = pd.MultiIndex.from_product(
[[2013, 2014], [3, 1, 2]],
names=['year', 'visit'])
# columns for clients and tyre pressure
columns = pd.MultiIndex.from_product(
[['Bob', 'Sue'], ['Front', 'Rear']],
names=['client', 'tyre pressure'])
# mock some data
data = 2 + np.random.rand(6, 4)
# create the DataFrame
mechanics_data = pd.DataFrame(data, index=index, columns=columns)
mechanics_datagénérons les données¶
dans ce premier code nous avons créé les données directement dans la bonne forme
mais en pratique ce qu’on fournit en général c’est plutôt une table qui ressemble à ceci
# voici comment on pourrait produire une table
# qui serait plus conforme à la réalité
from itertools import product
names = ['Bob', 'Sue']
years = list(range(2013, 2015))
visits = list(range(1, 4))
tyres = ['Front', 'Rear']
# une compréhension de liste
data = [
# qui contient un dictionnaire par ligne
dict(name=name, year=year, visit=visit, tyre=tyre,
# ici on évite le coté "random" en incrémentant
# un peu à chaque pas; la pression est entre 2 et 3
pressure=2+index/25)
#
for index, (name, year, visit, tyre) in
# product pour parcourir le produit cartésien
# sur les 4 dimensions
enumerate(product(names, years, visits, tyres))
]df = pd.DataFrame(data)
dfpivot_table¶
typiquement la table du début, on l’aurait créée à partir des données brutes comme ceci
pivot = df.pivot_table(
values='pressure',
index=['year', 'visit'],
columns=['name', 'tyre'])
pivotstack/unstack¶
unstack()¶
unstack() va faire migrer un étage de l’index des colonnes (ici on a deux niveaux year et visit) vers l’espace des colonnes
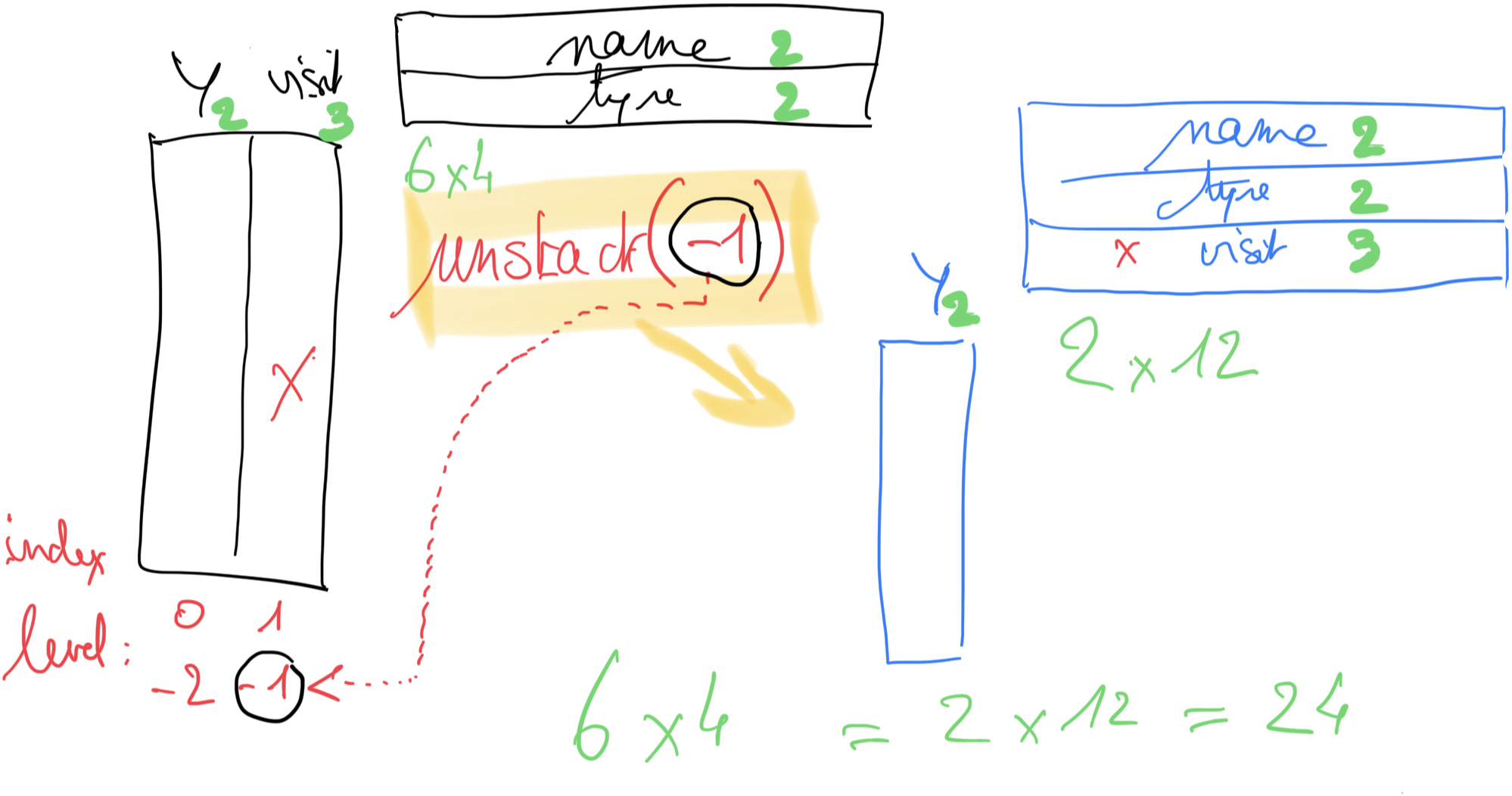
# unstack : on part de la dimension des lignes
# et dans cette dimension notre multi-index contient
# 0: year
# 1: visit (donc aussi -1 car le dernier)
unstacked = pivot.unstack(level=-1)
unstackedstack()¶
toujours à partir de la forme carrée 2x2 issue du pivot, dans l’autre sens, stack() va faire...
# ici stack part des colonnes vers les index
# donc les niveaux sont
# 0: name
# 1: tyre
# remarquez que je peux aussi bien utiliser le nom
# et que c'est sans doute préférable
stacked = pivot.stack(level='tyre')
stackedà la limite¶
si je persiste, en faisant encore une fois stack(), j’obtiens cette fois .. une série
# ici stack part des colonnes vers les index
# donc les niveaux sont
# 0: name
# 1: tyre
# donc level=-1 désigne le niveau 'tyre'
stacked2 = pivot.stack().stack()
type(stacked2)pandas.Serieset donc si vous avez suivi, le nombre de niveaux dans l’index de cette série, c’est ?
len(stacked2.index.levels)4produire le pivot à la main¶
voyons maintenant comment on pourait produire le pivot sans passer par pivot_table(), et donc de manière plus pédestre, en gérant nous mêmes les index et les unstack()
c’est surtout pour le sport bien sûr, pour bien comprendre.
# on repart de la donnée brute
df.head()la première chose à faire est donc de mettre les catégories en index
# et pour ça on peut faire par exemple
df_1column = df.set_index(['name', 'year', 'visit', 'tyre'])
df_1column.head()et là, il ne me reste plus qu’à faire quoi ?
je vous laisse réfléchir...
# ça marche pas trop mal, mais pas exactement
# car si je ne précise rien je vais avoir un arrangement
# qui dépend de l'ordre des niveaux dans l'index
# (unstack sans argument prend l'index=-1)
df_1column.unstack().unstack()df_1column.unstack("name").unstack("tyre")et groupby ?¶
ici on a pris des données dans lesquelles il n’y a pas de répétition (par ex., on a une seule donnée pour Bob/2013/Front/1), on n’a donc pas eu besoin de faire de groupement ni d’agrégation.
dans le cas général, pivot_table sait aussi faire de l’agrégation
voyons, toujours pour le sport, comment on ferait à la main une pivot_table dans ce cas-là
et pour ça on va prendre notre éternal titanic
import seaborn as sns
titanic = sns.load_dataset('titanic')
titanic.head()objectif¶
reproduire ceci sans utiliser pivot_table():
titanic.pivot_table(index='sex', columns='pclass', values='survived')groupby¶
regardons pour commencer le résultat d’un groupby avec ces deux critères, et qui agrège avec mean pour faire la moyenne
grouped = titanic.groupby(by=['sex', 'pclass']).survived.mean()
groupedsex pclass
female 1 0.968085
2 0.921053
3 0.500000
male 1 0.368852
2 0.157407
3 0.135447
Name: survived, dtype: float64on obtient donc une série parce que
avec
.groupbyon obtient une collection de dataframesen faisant
.survivedon s’est ramené à une collection de sériesen faisans
.mean()on s’est ramené à une collection de nombres (les moyennes)
et surtout ce qui nous intéresse ici c’est que l’index de cette série est de profondeur 2 (parce qu’on a donné 2 critères au groupby)
grouped.indexMultiIndex([('female', 1),
('female', 2),
('female', 3),
( 'male', 1),
( 'male', 2),
( 'male', 3)],
names=['sex', 'pclass'])pivot_table = groupby + unstack¶
et donc on peut tout simplement reproduire le premier pivot_table() en faisant
pivot2 = titanic.groupby(by=['sex', 'pclass']).survived.mean().unstack()
pivot2bon c’est beaucoup plus court et lisible avec pivot_table(), mais vous pouvez constater que c’est vraiment une fonction de confort uniquement, qui se refait assez facilement par d’autres moyens