in this TP we work on
data that represents periods and not just one timestamp
checking for overlaps
grouping by period (week, month, year..)
then later on, grouping by period and category
and some simple visualization tools
here’s an example of the outputs we will obtain
imports¶
import pandas as pd
import matplotlib.pyplot as pltmake sure to use matplotlib in interactive mode - aka
ipympl
# your codeoptional: setup itables, so that we can have scrollable tables
# your codethe data¶
we have a table of events, each with a begin (beg) and end time; in addition each is attached to a country
leases = pd.read_csv("data/leases.csv")
leases.head(10)adapt the type of each columns¶
surely the columns dtypes need some care
# your code# check it
leases.dtypesbeg str
end str
country str
dtype: objectraincheck¶
check that the data is well-formed, i.e. the end timestamp happens after beg
# your codeare there any overlapping events ?¶
it turns out there are no event overlap, but write a code that checks that this is true
# your codetimespan¶
What is the timespan covered by the dataset (earliest and latest events, and duration in-between) ?
# your codeaggregated duration¶
so, given that there is no overlap, we can assume this corresponds to “reservations” attached to a unique resource (hence the term lease)
write a code that computes the overall reservation time, as well as the average usage ratio over the overall timespan (usage ratio as in: 100% if it were used all the time)
# your codevisualization - grouping by period¶
usage by period¶
grouping by periods: by week, by month or by year, display the total usage in that period
(when ambiguous, use the beg column to determine if a lease is in a period or the other)
expected result
for now, just get the grouping right and produce something like e.g.
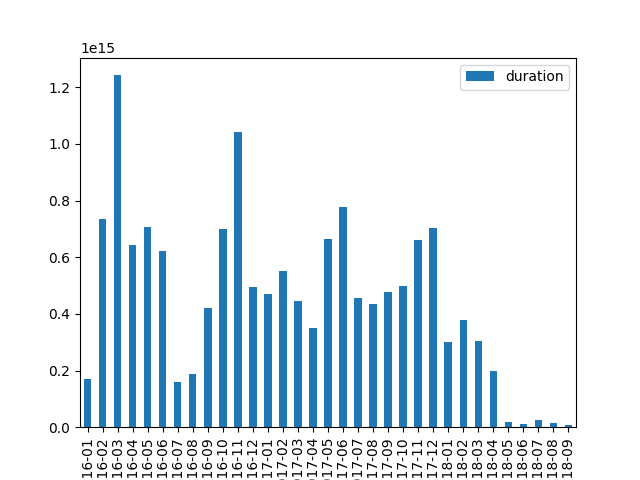
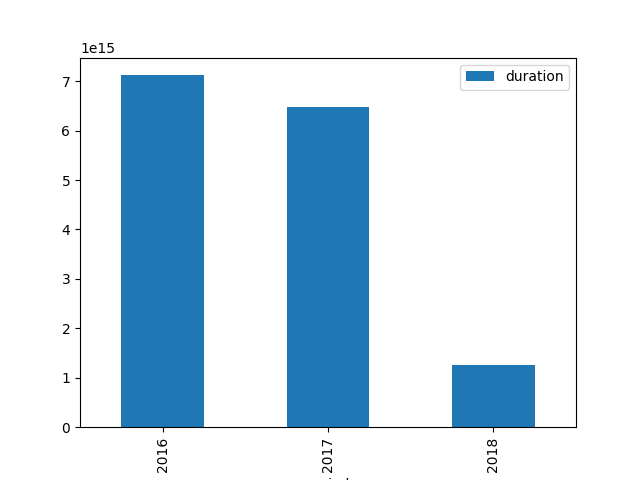
we’ll make cosmetic improvements later below, and the final results look like this, but let’s not get ahead of ourselves
hint
There are at least 2 options to do this grouping, based on resample() and to_period()
advanced users may wish to write them both and to comment on their respective pros and cons
# your codeimprove the title and bottom ticks¶
add a title to your visualisations
also, and particularly relevant in the case of the per-week visu, we don’t get to read the labels on the horizontal axis, because there are too many of them
to improve this, you can use matplotlib’s set_xticks() function; you can either figure out by yourself, or read the few tips below
a few tips
the object that receives the
set_xticks()method is an instance ofAxes(one X&Y axes system),
which is not the figure itself (a figure may contain several Axes)
ask google or chatgpt to find the way you can spot theAxesinstance in your figureit is not that clear in the docs, but all you need to do is to pass
set_xticksa list of indices (integers)
i.e. if you have, say, a hundred bars, you could pass[0, 10, 20, ..., 100]and you will end up with one tick every 10 bars.there are also means to use smaller fonts, which may help see more relevant info
# let's say as arule of thumb
LEGEND = {
'W': "week",
'M': "month",
'Y': "year",
}
SPACES = {
'W': 12, # in the per-week visu, show one tick every 12 - so about one every 3 months
'M': 3, # one every 3 months
'Y': 1, # on all years
}# your codea function to convert to hours¶
you are to write a function that converts a pd.Timedelta into a number of hours
read and understand the test code for the details of what is expected
use it to test your own implementation
# your code
def convert_timedelta_to_hours(timedelta: pd.Timedelta) -> int:
pass# test it
# if an hour has started even by one second, it is counted
test_cases = (
# input in seconds, expected result in hours
(0, 0),
(1, 1), (3599, 1), (3600, 1),
(3601, 2), (7199, 2), (7200, 2),
# 2 hours + 1s -> 3 hours
(7201, 3),
# 3 hours + 2 minutes -> 4 hours
(pd.Timedelta(3, 'h') + pd.Timedelta(2, 'm'), 4),
# 2 days -> 48 hours
(pd.Timedelta(2, 'D'), 48),
)
def test_convert_timedelta_to_hours():
for seconds, exp in test_cases:
# convert into pd.Timedelta if not already one
if not isinstance(seconds, pd.Timedelta):
timedelta = pd.Timedelta(seconds=seconds)
else:
timedelta = seconds
# compute and compare
got = convert_timedelta_to_hours(timedelta)
print(f"with {timedelta=} we get {got} and expected {exp} -> {got == exp}")
test_convert_timedelta_to_hours()with timedelta=Timedelta('0 days 00:00:00') we get None and expected 0 -> False
with timedelta=Timedelta('0 days 00:00:01') we get None and expected 1 -> False
with timedelta=Timedelta('0 days 00:59:59') we get None and expected 1 -> False
with timedelta=Timedelta('0 days 01:00:00') we get None and expected 1 -> False
with timedelta=Timedelta('0 days 01:00:01') we get None and expected 2 -> False
with timedelta=Timedelta('0 days 01:59:59') we get None and expected 2 -> False
with timedelta=Timedelta('0 days 02:00:00') we get None and expected 2 -> False
with timedelta=Timedelta('0 days 02:00:01') we get None and expected 3 -> False
with timedelta=Timedelta('0 days 03:02:00') we get None and expected 4 -> False
with timedelta=Timedelta('2 days 00:00:00') we get None and expected 48 -> False
# for debugging; this should return 48
convert_timedelta_to_hours(pd.Timedelta(2, 'D'))use it to display totals in hours¶
keep the same visu, but display the Y axis in hours
btw, what was the unit in the graphs above ?
# your codegrouping by period and region¶
the following table allows you to map each country into a region
# load it
countries = pd.read_csv("data/countries.csv")
countries.head(3)a glimpse on regions¶
what’s the most effective way to see how many regions and how many countries per region ?
# your codeattach a region to each lease¶
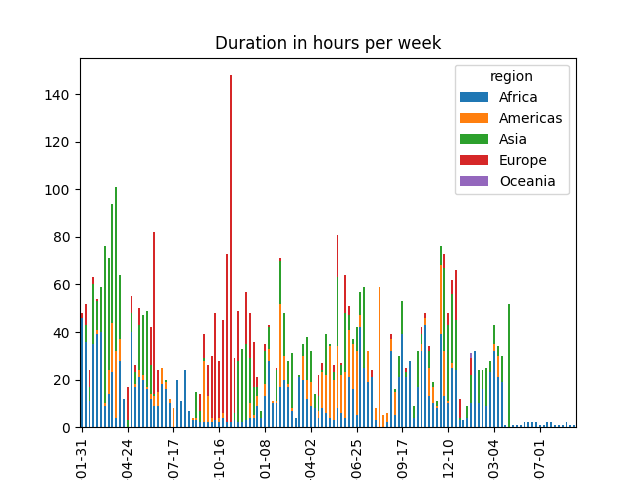
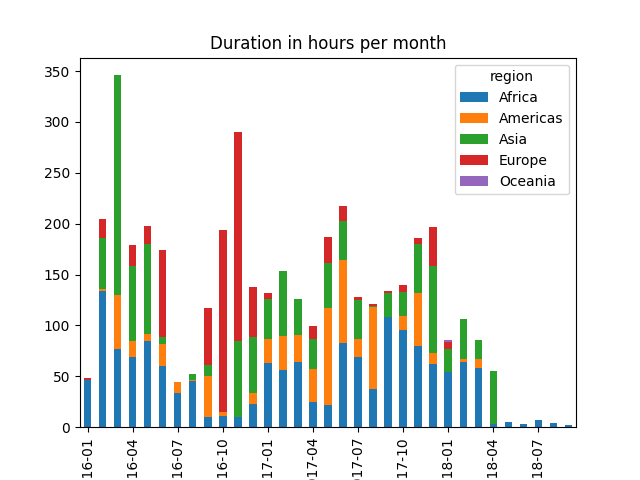
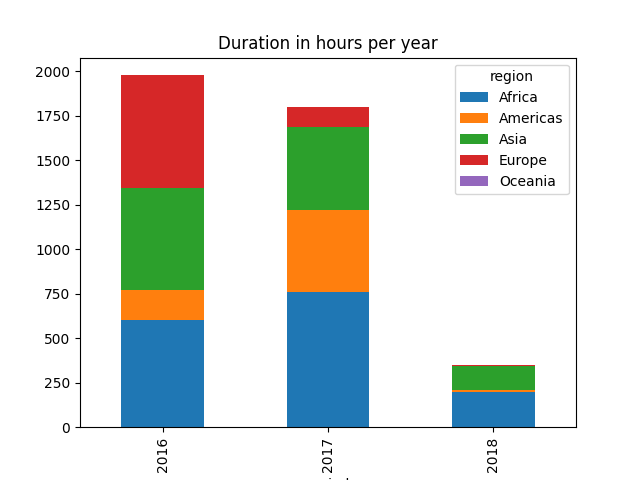
your mission is to now show the same graphs, but we want to reflect the relative usage of each region, so we want to split each bar into several colors, one per region see expected result below
most likely your first move is to tag all leases with a region column
# your codevisu by period by region¶
you can now produce the target figures, again they look like this
# your code